バックエンドにAWS Lambdaを使ってサーバレスな動的サイトを作った
by @dekokun on 2015/07/05 8:17
Tagged as: AWS.
どうも。もう一つのブログの方に書いていたのですが、東京から京都まで歩いて行くことになりまして、私の位置情報が把握しやすいようにサイトを作りました。なお、明日(7/6)出発します
このためだけにサーバを構築しサーバ代を払うのは馬鹿らしいと思いまして、なんとかサーバを構築せずにある程度安く済ませることはできないかと考えた結果、バックエンドをAWS Lambdaに任せてサイト自体はS3上に構築するという形にしました。
なお、「バックエンドをAWS Lambdaに任せた」といった場合、普通はクライアントのAWS SDKからLambda関数をキックするようなものになるかと思いますが、今回はLambda関数を無限ループのバッチ的に使い、クライアントはS3を経由してその結果を取得するような作りにしています。詳しくは以下。
あと、後述しますが「結局何かしらでLambdaを使いたかったネタ設計」みたいなところはありますのでご了承ください。
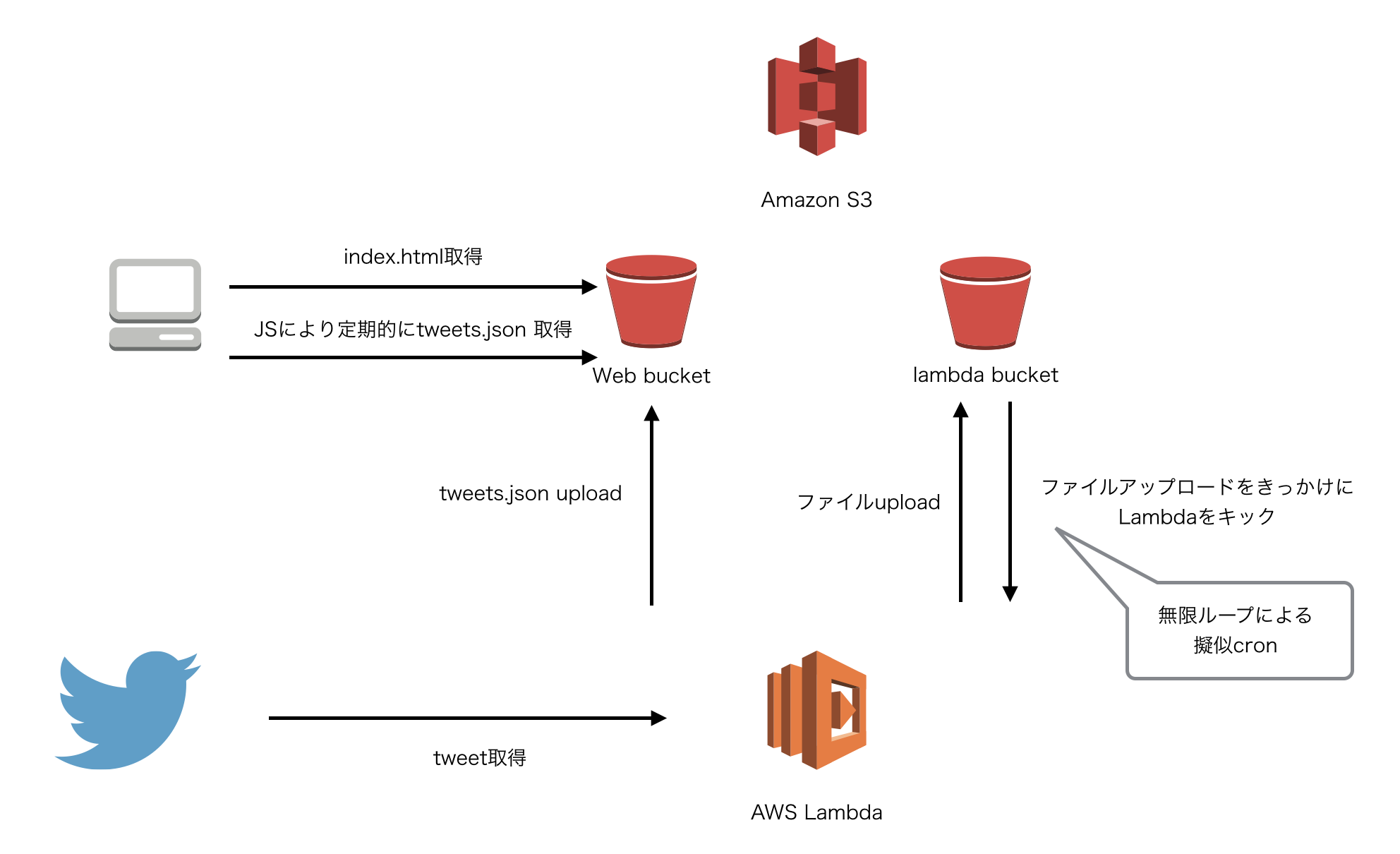
構成
以下図をみてもらったほうが早いかもしれませんが、以下のとおりです。
バックエンド
AWS Lambdaをcronの代わりに使ってみるよを参考にしています。
- AWS Lambdaを最初に手動でキックする
- 登録してあるLambda関数が動きtwitterのAPIから私のtweetを取得、Web用のS3 bucketにjson形式でアップロードする
- 上記Lambda関数が最後にLambda用のS3 bucketにファイルをアップロードする
- Lambda用のS3 bucketへのファイルアップロードイベントがLambdaに通知される (2. に戻る。無限ループ)
フロントエンド
- ブラウザがS3からindex.htmlを取得
- index.htmlのJSから定期的にLambdaによってアップデートされたjsonファイルを取得して地図に反映
構成図
料金
大雑把に言うとS3のデータ転送量及びデータへのリクエスト数と、Route53のクエリ数、Lambda関数の実行回数と実行時間に対して料金がかかっていますが、Lambda関数は月の無料枠に収まるレベルになっておりまして、これからの転送量にもよりますが、現在はだいたい1日あたり0.05ドルな感じです。月に1.5ドルくらいでこんな環境ができるなんて嬉しいですね。
S3へのPUTリクエスト数による課金が比較的高いです。現在、tweets.jsonは以前と内容が同じでも毎回S3にtweets.jsonをPUTしているのですがそれをなくせば更に安くなる模様。もう明日の朝には京都に向けて出発するのでそちらを修正するのはやめておきます。
Lambdaで良かったこと
テストが結構簡単
例えばindex.jsのhandlerを登録しているような環境のテストがしたい場合は、手元の環境でLambda関数に渡しているロールとと同じ権限を付与して、以下みたいな形で簡単にテストできます。いいね!
var main = require('./index');
var context = {done: function(var1, var2) {console.log(var1), console.log(var2)}}
main.handler('イベントデータ', context);デプロイが結構簡単
以下のコマンドを実行するだけでデプロイできちまうので非常に簡単でした。
rm -f lamda.zip && zip -r lambda.zip index.js node_modules && aws lambda update-function-code --function-name 関数名どうぞ --zip-file fileb://./lambda.zip --region ap-northeast-1 | jq '.'
npm run deployで実行できるようにして超楽だった。npmのscripts便利。
Lambdaでハマったところ
結構ハマりどころは多かったです。まぁ、一度わかると超便利ではあるのですが…なかなか…
sourceを指定してなかった
Lambda関数を登録するだけ登録して、event sourceを追加せず、「自分でinvokeするとうまくうごくけどS3にファイルをアップロードしても動かないなぁ」「ってか、全てのS3へのイベントが全部通知されるのか!やばいな!!」と悩みました。そんなわけありませんでした。
Management ConsoleのLambdaのところからAction -> Add event source で必要なイベントソース(今回だと、S3のlambda用bucketへのPUTの通知)を追加することで動くようになりました。
zipにする際にフォルダごとzipにしてて怒られた
Lambda関数はzipをアップロードして登録することができるのですが、その際に、最初はindex.jsが存在しているディレクトリごとzipコマンドにかけてアップロード(例: zip -r lambda.zip lambda_dir)していたのですがそれではダメで、zip -r lambda.zip index.js node_modulesみたいに、直接index.jsをzipしてあげる必要があります。
まぁ、そりゃ、アップロードされる側もzipされたディレクトリの名前なんて知らねぇでしょうし当然といえば当然なのですが、少し悩んだ。
S3にputobjectする際にACLをいじろうとしたら失敗した
Lambda関数、登録する時にその関数が動く際の権限をroleで付与するのですが、結構賢くて「S3に何かするならいい感じにロールを作ってやるよ」みたいな感じでロールを作ってくれます。
S3へのPUTとGETが行える権限(s3:PutObject及びs3:GetObject)はついてくるのですが、PUTする際にACLを付与する権限(s3:PutObjectAcl)はついてきません。
ですので、PUTする際にACLを指定する際は、ロールにs3:PutObjectAclを付与してあげる必要があります。
注意
実際のところ、この無限ループによる擬似cronは信頼性が死ぬほど低い(変なところでcrashしたら最後、一生起動しない)ので、商用環境などでは絶対に使えません。というか、今回の私の目的に合致したものだったかどうかも怪しい。というか、合致していない。ま、楽しかったしいっか。
想定される質問
これは本当に「動的サイト」と言えるものなのか
答:まぁ、静的サイトじゃないし…動的サイトなんじゃないかな!!!!
こんなまわりくどいことしなくてもJSから直接@dekokunのツイートを取得しにいけばいいのではないか
答:東京から京都までの旅はだいたい15日〜20日くらい、その間にツイートする件数は何件になるか想像もつかない状態でJSからtwitterに問い合わせまくるよりも、こっちで一旦保持しておいたほうがいろいろと便利だろうと思ってこちらの構成にしております!!!
tweetが累積した場合かつ上記サイトがたくさんの人に見られた場合、定期的にそれをクロールされると通信料やばくなるんじゃ…
答:その通り!せめて、tweets.jsonはIDだけ保持して、それが変化したらさらに別の所に問い合わせるとかしたほうがよかった!!!が、まぁ、実際通信料が増大してきたらクロールの間隔を下げる方向で対応するしかないね…もう明日には出発だもんね
CloudFront使わないの?
答:tweets.jsonが更新されたタイミングでinvalidationするっていうのさえちゃんとすればCloudFrontいいですね!!!!!!今回は時間がなくてやってないけど!!!!
擬似cronって…AWS Data Pipelineは使わないの?
答:Data Pipelineはcron的に使おうとすると15分に1回しか動かせないし、EC2経由で実行されるため結構お金がかかる
この構成、やろうとしていることに対してクソな構成なのでは?
答:そのとおりですね!!JSONをS3を介して渡しているためWebSocketも使えず、前時代的なポーリングによる解決になってしまいましたし、上記あるようにcronの信頼性は著しく低いですし、無駄に構成が複雑になっている感ありますし…ま、仕事じゃないし、とにかくLambdaを使いたかったって感じですね!
感想
明日から京都に向けて歩き始めるから早く寝ようと思っていたが結構遅くなりつつある。いかんいかん。
以下のブログで実況中継しているので、皆さん応援してね!!
でこらいふろぐ http://dekolife.hatenablog.com/
応援してね!!応援してね!!!!
comments powered by Disqus Send to Kindle
Send to Kindle- ツイート
